
In recent years we’ve seen an explosion in the number of sensors and embedded computer devices being used by consumers and in a range of industries.
New cars have several computers and sensing capabilities built in, including anti-lock braking systems (ABS), automatic lights that turn on in dark areas, and automatic windscreen wipers that detect rain.
Most of us have mobile phones with an integrated camera, and GPS and electronic gyros are now standard extras. We can now even use small robots to automatically vacuum-clean the floor when we’re not home.
All of these devices and their ability to collect data pose a challenging and unprecedented question – the so-called Big Data question. That is, we’ve now got more data at our fingertips than ever before, but how do we make sense of it?
More is more?
While more data is being created than ever before, the availability of information does not necessarily ensure good or efficient use of such devices and the data they collect.
In addressing the Big Data question we need to consider several factors, including:
- how we can combine information from different sources in a computational manner to maximise performance
- how we can construct statistical representations of the world that account for scientific uncertainty
- how we can make collaborative decisions that take into account the inherent uncertainties and multiple goals of data-intensive problems
While the amount of data collected at a consumer level is staggering, there is a greater imperative to understand and make use of Big Data in the industrial world. In big industries – such as mining and energy – better use of available information could lead to greater efficiencies.
Underground data
Geothermal energy has the potential to deliver vast quantities of clean energy in Australia and can significantly reduce our carbon footprint.
This is possible by locating and extracting heat from hot dry rocks (HDRs) found in different parts of the continent.
But these rocks sit at a depth of 5km or more and locating them precisely involves expensive drilling programs. If we can use the data from better sensors to minimise the amount of drilling necessary to locate the HDRs, it would reduce the overall financial costs and resource use for geothermal exploration.
To tackle this problem, myself and my fellow researchers from NICTA and the School of Information Technologies, University of Sydney are working closely with the Earth Schools at Australian National University, University of Melbourne and University of Adelaide to develop machine-learning techniques – a branch of AI – to maximise the usage of information from multiple sources.
We do this by combining multiple sets of data into one single statistical model. Take geothermal exploration, for example.
Immense quantities of data are available from across the country, datasets that consist of geophysical surveys and drilling data, collected over several decades. They typically contain data about the concentration of radioactive minerals such as thorium, uranium and potassium, data about changes in the magnetic field, and data from the changes in the earth’s gravitational field.
When combined, these datasets contain several terabytes of information. Our biggest challenge is to design efficient algorithms that extract relevant information from geophysical surveys and drilling data, to infer the geothermal potential of regions at least 5km below the surface.
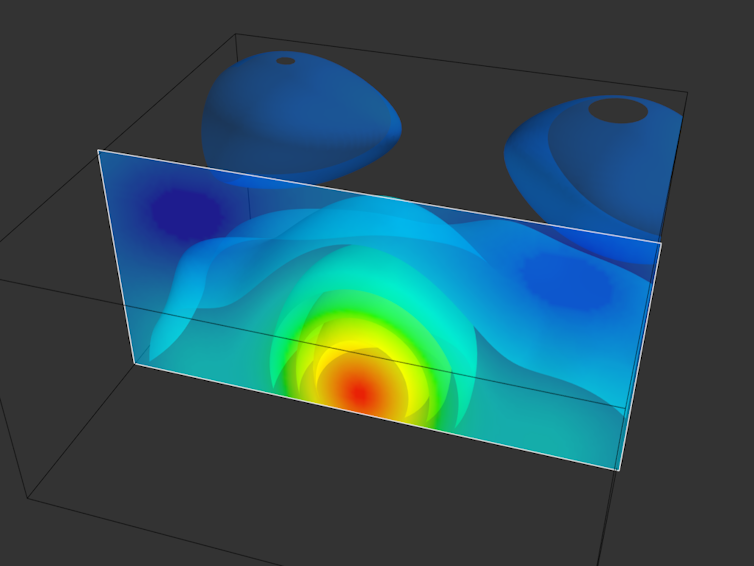
As mentioned, this technique relies on modern statistical machine learning. In particular, “nonparametric Bayesian approaches” - statistical computer analyses that can automatically find and “learn” relationships between complex and changing sets of data and estimate the uncertainty associated with them.
The advantage of creating one statistical computer model that can process all this information is the ability to model the interdependencies between different data sets simultaneously. This could reduce uncertainty and therefore the risks associated with data gathering and drilling.
The ability of intelligent systems within devices to constantly update their understanding about the environment by collecting and analysing complicated data sets will become essential as they become more common and interact more closely with people.
And while we may not have all the answers to the Big Data question, our method of processing multi-modal information could become the next foundation for advances in geothermal exploration.
Who knows how it could also alter our use of consumer-generated data.